Differences between ASR and TTS – how to choose technologies for call quality

Differences between ASR and TTS – how to choose technologies for call quality
Modern communication is increasingly happening via voice. According to reports by Gartner and Deloitte, the market for intelligent voice technologies is growing at a rate of over 20% per year, and by 2030 it may reach a value of 80–100 billion dollars.
We make phone calls, dictate messages, talk to voice assistants, and sometimes even handle official matters through an automated system that really understands us and is able to respond to our query in a natural way. Behind all of this stand two technologies: ASR (Automatic Speech Recognition) and TTS (Text-to-Speech). One listens, the other speaks. Together, they can create a system that carries on a conversation almost like a human.
But for this to work well, you need to know how ASR and TTS differ, how they work, and how to match them to a specific type of conversation.
Speech Recognition Technology (ASR), or how a machine “hears” a human
ASR technology is responsible for automatic speech recognition. In practice, this means that the system listens, analyzes the sound, and converts it into text. If you say, “I’d like to be connected to the sales department,” ASR captures these words, “understands” their meaning, and passes them on – to a bot, CRM, or agent. This is where the role of natural language processing begins, which allows the system to understand the sense of the utterance and not just individual words.
Does it sound simple? Only at first glance. In reality, this process is powered by complex acoustic and language models and neural networks based on machine learning. The system not only hears the sound, but must also identify the language, accent, speech rate, and intonation.
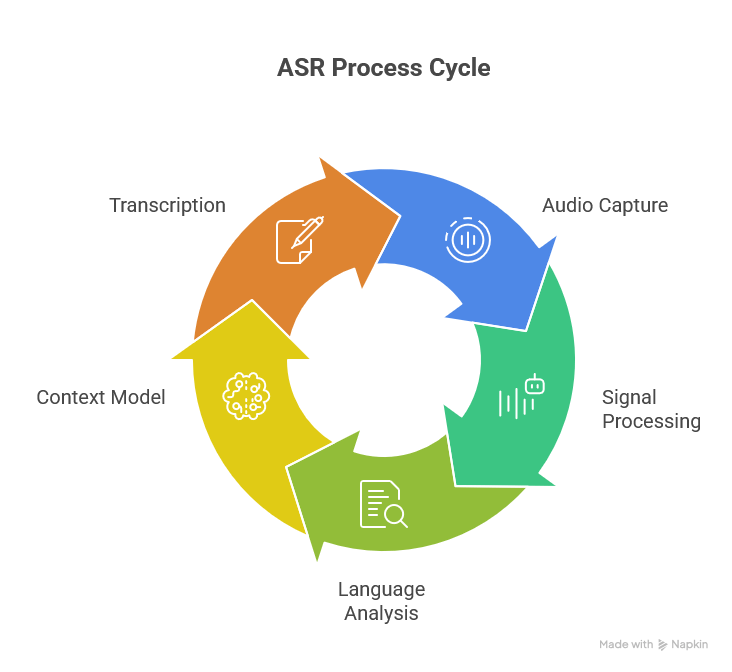
How ASR works step by step:
- Audio capture – the microphone or phone transmits the audio signal.
- Signal processing – the system splits the audio into short fragments and converts it into acoustic features.
- Language analysis – algorithms match sounds to words from the database.
- Context model – thanks to NLP, the system checks which words fit together.
- Transcription – the final text is generated, which can then be processed further.
What affects ASR quality?
- Quality of the microphone and acoustic environment – noise, echo, and interference can seriously hinder recognition.
- Industry-specific vocabulary – a medical system has to recognize different words than a courier service system.
- Language model – the better it is adapted to a given industry or country, the higher the accuracy.
- Accent and diction of the user – ASR learns different pronunciation variants, but local accents are still a challenge.
- Language and context – the system must understand that a “bill” can mean an invoice, but also a bank account statement.
In practice, the best solutions achieve accuracy exceeding 95%, provided they have a well-tuned acoustic and language model.
TTS and Speech Synthesis Engines – when technology starts speaking like a human
If ASR listens, TTS speaks. TTS, or Text-to-Speech, converts text into speech. It is the technology that enables automatic systems to respond to users in a natural and friendly manner.
In the past, TTS voices sounded mechanical, like an old announcement system reading out train numbers. Today, thanks to AI and so-called neural speech synthesizers, TTS can convey emotions, pace, and even the character of the speaker.
How TTS works in practice:
- Text analysis – the system checks syntax, punctuation marks, and the intent of the sentence.
- Phonetic transcription – the text is converted into phonetic symbols that describe how words should be pronounced.
- Audio generation – the TTS engine creates a sound wave, reproducing a voice with a defined timbre, pace, and intonation.
- Personalization – the user (company) can choose the tone, emotions, gender, or accent of the voice.
What affects TTS quality?
- Naturalness and fluency – the voice cannot be too “robotic”; it should sound emotional.
- Intonation and pauses – these determine whether the utterance is clear and pleasant to listen to.
- Speed of speech generation – response time matters in a live conversation.
- Personalization – brands increasingly create their “own” TTS voices, for example a bank that always speaks with the same voice in the app and on the helpline.
Examples of TTS applications:
- Hotlines and voicebots – automated responses and announcements.
- Navigation and voice assistants – e.g. Siri, Alexa, Google Assistant.
- Education and accessibility – TTS facilitates access to content for blind or visually impaired users.
- Audio marketing – brands create voice ads tailored to the customer’s style.
ASR and TTS – a duo that enables searching, understanding, and speaking in the user’s language
ASR alone without TTS would be like talking to a deaf secretary, and TTS alone would be a monologue. Only the combination of both technologies delivers full conversion – not just sound into text, but also emotions into user experience. This is how a voicebot works, for example, when it can understand a question, process data, and respond with a voice.
A real-life example:
Customer: “I’d like to check the balance of my account.”
ASR: recognizes the words and passes the text to the banking system.
System: retrieves the account data.
TTS: responds with a voice saying, “Your balance is 3,450 zloty.”
The entire process takes less than a second, and the customer does not feel as if they are talking to a machine. This does not mean, however, that consultants are unnecessary. They solve problems that technology is not able to handle. The best solution is therefore human + bot.
How to select ASR and TTS voice systems for the type of conversation
Not every conversation requires the same technology. What works in a phone survey may completely fail in VIP customer service. Therefore, it is worth matching the system to the goal of the conversation and the user’s expectations.
24/7 customer service
- Goal: fast, natural conversation that is understandable for every user.
- Recommendation: ASR with a wide range of accents + a natural, neutral TTS voice.
- Tip: use a warm voice tone (not too formal) and short sentences.
Sales voicebot
- Goal: emotional engagement and persuasion.
- Recommendation: TTS with clear modulation and an intonation that encourages action. ASR must react instantly, without long processing.
Medical and financial industries
- Goal: maximum accuracy and data security.
- Recommendation: ASR trained on industry-specific data (understands terminology). TTS – calm, formal tone.
IVR systems (voice menus)
- Goal: simplicity and speed of service.
- Recommendation: ASR that recognizes short commands such as “1,” “complaint,” “connect to consultant.”
- TTS should be clear and rhythmic.
Educational or e-learning applications
- Goal: comprehensibility and engagement.
- Recommendation: TTS with different voices and emotions to keep the learner’s attention. ASR is useful for pronunciation practice.
How to test voice call quality
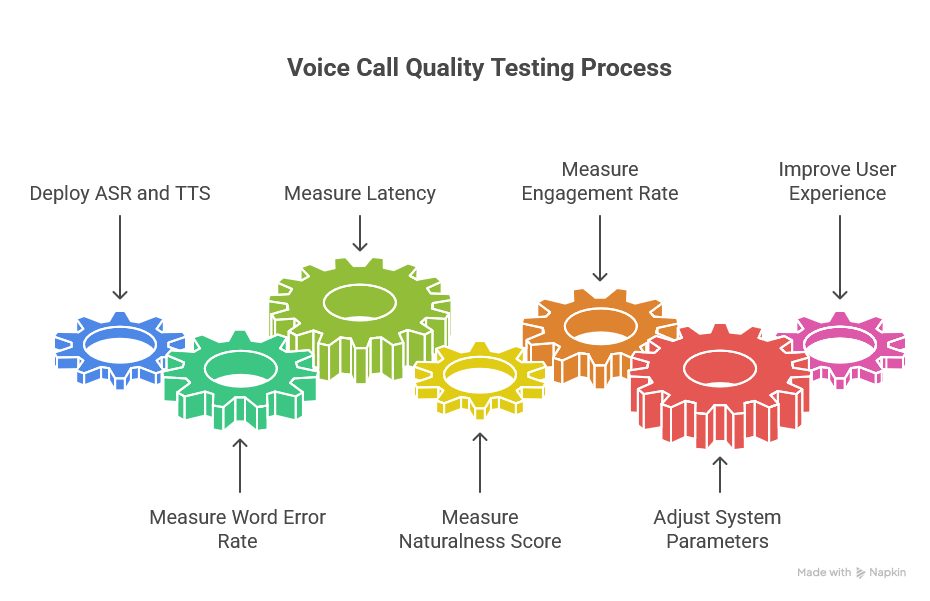
The deployment of ASR and TTS is only the beginning. The key is to monitor the quality of conversations and continuously improve it.
What to measure?
- Word Error Rate (WER) – the percentage of incorrectly recognized words (the lower, the better).
- Latency – system response time (delay between question and answer).
- Naturalness Score – rating of how “human” the voice sounds.
- Engagement Rate – whether users end the conversation satisfied or hang up.
With these indicators, you can precisely adjust system parameters and improve the user experience of conversations.
Porozmawiaj z naszym specjalistą
Personalization and voice branding
Voice is becoming a new element of brand identity. More and more companies are investing in personalized TTS voices that are as recognizable as a logo or brand color.
Example:
- A bank uses the same voice in its mobile app, IVR, and audio ads.
- A courier company uses a characteristic, friendly tone, thanks to which the customer immediately “recognizes” that they are talking to that company’s bot.
This is called voice branding – building trust and consistency in communication through sound.
Challenges and limitations of ASR/TTS
Although the technology is developing rapidly, there are still barriers:
- Accents and dialects – in Polish, differences between regions can be significant.
- Noise and interference – conversations in a car, on the street, or with loud music in the background are a major challenge for ASR.
- Homophones and context – words that sound similar can cause errors.
- Emotions and sarcasm – TTS does not always correctly interpret emotional nuances and tone.
- Privacy and security – voice recordings are personal data and must be processed in accordance with GDPR and cloud security principles.
The future of ASR and TTS – where is this heading?
Just a few years ago, speech recognition systems were associated with clunky solutions – like an IVR that asks: “Repeat: yes or no.” Today, the situation is completely different. Thanks to artificial intelligence, language models, and cloud computing, ASR and TTS technologies are developing at a rapid pace. And this is only the beginning of the voice revolution that is changing how companies communicate with customers. Let us take a look at what we can expect in the near future:
- Neural models and voice personalization
Modern TTS systems increasingly use neural voice models (Neural TTS). These models make it possible to generate voices that not only sound natural, but are also capable of expressing emotions such as surprise, empathy, or enthusiasm.
Combined with “voice cloning” technology, companies can create unique brand voices – proprietary, distinctive, and at the same time fully synthetic. Interestingly, some systems can already mimic the user’s accent, making the conversation feel more “local” and natural.
- Multilingual conversations and real-time translation
Imagine calling a foreign company and speaking Polish, while the person on the other end hears you in English. With no pauses and no delay. This is not science fiction. The first such systems already exist.
By combining ASR (speech recognition), NMT (neural machine translation), and TTS (speech synthesis), it is possible to conduct conversations across languages in real time. Solutions of this kind are already being tested by Google, Meta, as well as startups from the USA and Asia.
- Integration with multimodal AI
The next step is the integration of ASR and TTS with so-called multimodal AI – systems that can simultaneously analyze sound, text, images, and context. For example, an assistant in a call center not only hears the customer’s tone of voice, but also interprets their emotions in real time and adjusts its response tone accordingly.
This is no longer just a conversation. It is understanding emotions and the situation. The bot will be able to instantly detect irritation in the customer’s voice and automatically switch its tone from “sales-oriented” to “supportive.”
- Zero-shot and self-learning ASR models
Traditionally, ASR models had to be trained for a long time on massive datasets. A new generation of systems, so-called zero-shot ASR, can recognize speech in languages they have never “heard” before.
Thanks to LLMs (Large Language Models), the system analyzes context, tone, and sentence structure – and automatically matches the meaning. In practice, this means lower costs, shorter implementation time, and much higher flexibility.
ASR and TTS systems in Practice – how to use them to handle hundreds of calls at once
Before deploying a voicebot, it is worth asking yourself a few questions.
- Define the goal – what is the system supposed to do? Serve customers? Sell? Verify data?
- Choose technologies – check whether you need real-time ASR or whether offline is enough.
- Choose a provider – EasyCall, Deepgram, or maybe ElevenLabs?
- Prepare training data – the more examples of conversations from your industry, the better the model.
- Test with users – before you roll the system out on a large scale.
- Optimize – collect feedback, analyze conversations, and continuously improve accuracy.
Why call quality is the key to success
In the era of automation, every contact with a customer is worth its weight in gold. If your voicebot sounds artificial and ASR misrecognizes words, the customer will simply hang up. But if the conversation flows smoothly, naturally, and without errors, the user may not even notice that they are not talking to a human. It is the quality of the conversation that determines whether the technology supports your business or damages your brand image.
Time for something new
ASR and TTS today are more than just technical tools. They are the foundation of communication in a world where voice is becoming a new interface, just as important as a touchscreen or keyboard. It is therefore worth investing not only in the technology itself, but also in adapting it to people. Because in the end, it is not the machine that should be satisfied with the conversation, but the human on the other side of the line.
EasyCall provides modern voice systems designed to support your business. See what benefits they brought to Gizińscy Medical Center or Hotel Krokus. Get to know our experts and schedule a free consultation today.